WAT IS ROBOTS.TXT EN HOE STEL JE HET IN VOOR SEO?


Jouw bezoekers bied je het liefst alleen alle waardevolle en belangrijke pagina’s van je website. Daarom wil je ervoor zorgen dat irrelevante pagina’s juist geen aandacht krijgen van bijvoorbeeld Google. Denk bijvoorbeeld aan bedankt-pagina’s na het plaatsen van een bestelling of de beheerdersomgeving van de website. Wat je dan kan doen is het instellen van een robots.txt bestand. Hierin geef je zoekmachines richtlijnen voor het wel, dan wel niet laten crawlen van je website. Het goed inrichten van je robots.txt is daarom belangrijk voor het verbeteren van SEO. In dit artikel lees je alles over robots.txt.
Meer weten over de robots.txt? Wij leggen het je uit!
Robots.txt refereert naar een tekstbestand met richtlijnen waarmee je aan crawlers kunt aangeven hoe ze jouw website eenvoudig en efficiënt kunnen crawlen. Robots.txt maakt deel uit van het Robot Exclusion Protocol (REP): een verzameling van standaarden over de manier waarop websites communiceren met website crawlers. Zoekmachines maken namelijk gebruik van die crawlers, ook wel bots genoemd, die alle websites afstruinen en opslaan in een database. Bij gebrek aan een robots.txt bestand (en andere richtlijnen), gaan de crawlers ervan uit dat ze de hele website mogen scannen (crawlen). Het is niet altijd wenselijk om je gehele website gecrawld te hebben.
Let op: het robots.txt bestand betreft richtlijnen. De crawlers van grote zoekmachines respecteren het robots.txt bestand, maar kwaadwillende partijen kunnen het omzeilen. Het robots.txt bestand is dus niet geschikt om toegang tot vertrouwelijke informatie te ontzeggen.
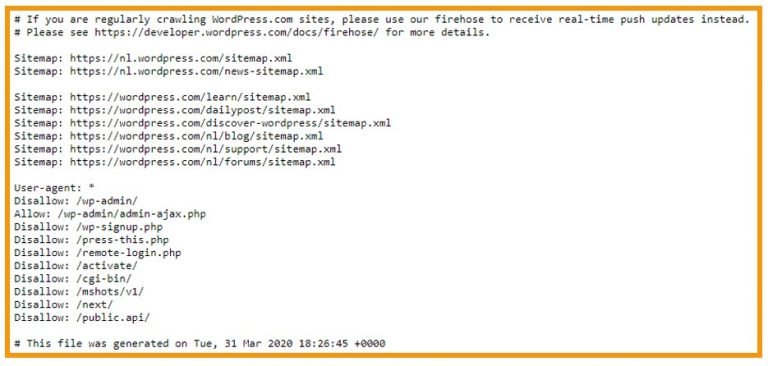
Voorbeeld van een robots.txt bestand
Het crawlen van de website belast de servers van zowel de zoekmachine als de gecrawlde website. Door het instellen van een robots.txt bestand zorg je er enerzijds voor dat je eigen website server niet overladen wordt door de verzoeken van bots en anderzijds dat de crawlers geen tijd en serverruimte verspillen door onnodige delen van de website te crawlen. Hoe efficiënter een robots.txt bestand is ingesteld voor crawlers, hoe minder serverruimte voor beide partijen wordt verspild en hoe eenvoudiger het voor bots wordt om jouw website uit te lezen.
Wat is crawlbudget? Crawlers krijgen een zogenaamd crawl budget toegewezen: een limiet van hoe vaak crawlers jouw website bezoeken en hoeveel pagina´s van een website ze scannen. Het crawl budget kan iedere dag licht variëren en is op te zoeken in Google Search Console. Voordat een crawler een website scant kijkt het allereerst naar het robots.txt bestand, indien ingesteld. Wanneer deze niet ingesteld is, scannen de robots de gehele website. Dus ook pagina’s die niet relevant zijn voor de meeste bezoekers, zoals de bedankt-pagina’s en beheeromgeving. Hartstikke zonde van het crawl budget dus, want die aandacht geven we liever aan alle belangrijke pagina’s van de website. Zodra er meer crawlbudget overblijft voor deze pagina’s zullen deze ook vaker gecrawld worden.
Het crawl budget zelf is geen factor die direct invloed heeft op je rankings, maar toch heeft het instellen van een robots.txt meerdere voordelen voor SEO. Met een robots.txt-bestand kan je de crawlers namelijk ook naar je sitemap leiden, een handleiding met alle pagina’s binnen je website. Dit geldt voor alle soorten webpagina’s, dus ook blogartikelen, nieuwsberichten, referenties, etc. Door crawlers de juiste weg te wijzen en irrelevante pagina’s uit te sluiten, kunnen nieuwe pagina’s sneller en beter geïndexeerd worden.
Een site audit is een technische scan van je website, waardoor je vervolgens alle technische problemen uit je site kunt halen. Dit is een cruciaal onderdeel binnen SEO. Het controleren van je robots.txt zou een onderdeel moeten zijn in je technische site audit. Het geeft namelijk inzicht in de manier waarop bepaalde pagina’s juist wel of juist niet goed worden uitgesloten en of dit wel op de juiste manier is doorgevoerd. Een fout zit hier namelijk in een klein hoekje, maar kan wel een grote impact hebben. Daarom is het belangrijk om je robots.txt in te stellen op een juiste manier.
Voordat een crawler of bot een website bezoekt, gaat het eerst het robots.txt-bestand na. Aan de hand van de crawler instructies die in dit bestand worden gegeven, hoeven de bots namelijk bepaalde delen van de website niet te crawlen. Deze instructies zijn richtlijnen voor de zoekmachine bots en sluiten dus geen bezoeken uit. Naast de instructie(s) zelf, is het ook mogelijk om voor iedere bot een andere instructie mee te geven. Ook is het mogelijk om de locatie van je XML sitemap aan te geven. Dat is geen vereiste, maar heeft als voordeel dat elke zoekmachine je sitemap dan direct kan vinden.
In essentie zien robots.txt-bestanden eruit als volgt:
User-agent: [naam van user-agent]
Disallow: [URL querystring die niet gecrawld moeten worden]
Samen vormen deze twee regels de basis van elke robots.txt-bestand. Let op dat de URL voor het robots.txt bestand hoofdlettergevoelig is en dat je robots in meervoud schrijft (dus niet robot.txt). Je kunt het robots.txt bestand veel uitgebreider maken door meer instructies toe te voegen aan specifieke User Agents. Gebruik telkens een nieuwe regel voor iedere instructie.
Tip: bekijk voorbeelden van hoe robots.txt eruit ziet
Een handige tip is om de robots.txt bestanden van andere websites te bekijken voor voorbeelden. Het is zeer eenvoudig te achterhalen hoe een robots.txt bestand van iedere website er uitziet, mits deze ingesteld is. Het robots.txt bestand is namelijk voor iedereen toegankelijk door “/robots.txt” achter de domeinnaam van een website te plakken. Het robots.txt-bestand van TO BE FOUND vind je bijvoorbeeld door “/robots.txt” achter tobefound.nl te plakken (https://tobefound.nl/robots.txt). Het robots.txt-bestand van TO BE FOUND ziet er als volgt uit:

Robots.txt bestand TO BE FOUND
Online marketing = uit je jas groeien
Er bestaan heel veel verschillende crawlers, zoals je kan zien in deze robots database. Daarom bepaal je in je robots.txt exact welke instructies je meegeeft aan welke crawlers, of wel user agents. Wanneer de instructies gelden voor iedere crawler, kan je het sterretje symbool [*] gebruiken. Hiermee zullen alle crawlers de instructies meenemen. Het kan zo zijn dat je voor meerdere web crawlers (andere) instructies wilt meegeven. Per web crawler (User Agent) kun je maar één groep met richtlijnen opgeven. Het geven van dezelfde instructies voor meerdere groepen in het robots.txt bestand kunnen de web crawlers niet begrijpen. Je moet dus per User Agent instructies opgeven, ook als er geen verschil is in de instructies. Het robots.txt wordt geaccepteerd door vrijwel alle grote zoekmachines, zoals Google, Yahoo, Bing en DuckduckGo. Het robots.txt bestand van Instagram laat goed zien hoe je instructies moet geven aan meerdere User Agents:
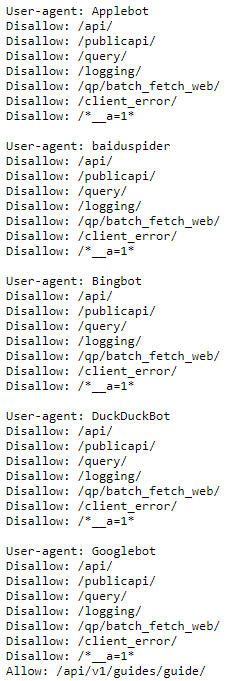
Robots.txt van Instagram
Als je een sitemap hebt, kan je de locatie van de sitemap aangeven aan het einde van het tekstbestand. Zoals in het onderstaande voorbeeld:
User-agent: *
Disallow: /voorbeeld/
Disallow: /voorbeeld2/
Sitemap: http://www.voorbeeld.nl/sitemap.xml
Hierdoor reik je bijvoorbeeld Google zo snel mogelijk de handleiding van jouw website toe. Het voordeel zit hem vooral in het feit dat de sitemap via het robots.txt bestand voor meerdere zoekmachines beschikbaar is. Alleen indienen via Google Search Console is daarvoor dus niet genoeg.
Alle content mag gecrawld worden. De instructies daarvoor zien eruit als volgt:
User-agent: *
Disallow:
Geen enkele content mag gecrawld worden. De instructies daarvoor zien eruit als volgt:
User-agent: *
Disallow: /
Deze optie is niet aan te raden voor het behalen van een hoge positie in Google, omdat je hiermee tegen Google zegt dat alle pagina’s vanaf de homepage niet gescand mogen worden.
Hierbij mag content gecrawld worden op basis van de instructies in het robots.txt bestand. Dat kan middels specifieke instructies per User Agent (zoals hierboven besproken) en de instructies “Allow” en “Disallow”.
Achter “Disallow:” kan je specificeren welke delen van de website je niet gecrawld wilt hebben. Het is niet nodig om de volledige domeinnaam te gebruiken, enkel het deel dat daarachter volgt. Stel je hebt een website genaamd ”www.voorbeeld.nl”, waarbij je wilt dat je webpagina met je geheime dagboek niet gecrawld wordt (www.voorbeeld.nl/geheimdagboek/). Dan zullen de instructies daarvoor er als volgt uitzien:
User-agent: *
Disallow: /geheimdagboek/

Stel dat je één hele mooie foto in je geheime dagboek hebt staan die je wél gecrawld wilt laten worden, dan kan je de “Allow” instructie specificeren.
User-agent: *
Disallow: /geheimdagboek/
Allow: /geheimdagboek/helemooiefoto.jpg
Hiermee vertel je dat de crawlers wel die ene hele mooie foto mogen crawlen, ook al mag de rest van het geheime dagboek niet gecrawld worden.
Let op! Deze Allow richtlijn wordt alleen ondersteund door de bots van Google en Bing. Zij bekijken namelijk de meest specifieke (langere) instructies.

Ieder teken dat opgenomen wordt in de instructies kan leiden tot een fout. Het is daarom een zorgvuldig in te vullen tekstbestand. Wij hebben websites voorbij zien komen waar per ongeluk de dissallow: / instructie was opgenomen, waarmee alle geïndexeerde pagina’s in gevaar werden gebracht. Bekijk altijd goed of geen ongewenste uitsluitingen worden opgenomen in de robots.txt.
Het is al eerder vermeld in dit artikel, maar het blijft belangrijk: het robots.txt bestand betreft slechts richtlijnen. Kwaadwillende partijen (bijvoorbeeld spambots) respecteren het bestand niet.
Daarnaast is het ook belangrijk om te weten dat een webpagina toch weergeven kan worden in de zoekresultaten, ondanks het instellen van een robots.txt. Dat kan komen doordat er bijvoorbeeld gelinkt wordt naar de desbetreffende pagina vanaf een pagina die wel gecrawld mag worden. De crawler scant dan de content van die pagina niet, maar neemt wel de URL op in de index. In Google wordt voor deze pagina’s geen meta description vertoont in de zoekresultaten, enkel de URL. Het is mogelijk om deze URLs tijdelijk (voor 90 dagen) te verwijderen via Google Search Console.
Google hanteert een limiet voor de bestandsgrootte van een robots.txt bestand, namelijk 500kb. Bij overschrijding wordt de inhoud na dit maximum genegeerd.
De robots.txt gebruik je om crawling van bots te voorkomen en zo crawlbudget te besparen. Om ervoor te zorgen dat een complete pagina niet geïndexeerd wordt, kan je de “noindex,nofollow” tag gebruiken. Het kan verwarrend zijn om het verschil tussen deze twee middelen te achterhalen. De noindex,nofollow meta tag werkt anders dan een robots.txt en zet je in wanneer je zeker wilt dat de pagina niet geïndexeerd wordt. Echter kunnen deze pagina’s nog wel gecrawld worden. Het robots.txt bestand biedt dus een oplossing voor het besparen van je crawl budget. De noindex,nofollow tag biedt oplossingen voor indexatieproblemen.
Er bestaan discussies rondom het wel of niet opnemen van een noindex tag in het robots.txt. Zo tweette Max Prin ooit een test, maar gaf John Mueller van Google specifiek aan dit niet aan te bevelen. Wij adviseren dan ook om dit niet te doen.
Wat nou als je er zeker van wilt zijn dat je pagina niet gecrawld wordt en ook niet geïndexeerd wordt? Gebruik je dan beide middelen? Nee, dat werkt niet. Zodra Google het robots.txt bestand uitleest komt het niet op die pagina door de disallow, waardoor het ook de noindex, nofollow tag niet zal kunnen zien. Daarom kan dan de pagina alsnog geïndexeerd worden. De beste methode is er naast een disallow in de robots.txt gewoon voor te zorgen dat de pagina vanaf de website dan ook niet meer toegankelijk is via interne links.
Wanneer je een robots.txt hebt gemaakt en wilt weten of die correct is ingesteld, zijn daar handige tools voor om het te controleren. Met de robots.txt tester van Google kan je controleren of je de juiste richtlijnen hebt meegegeven aan Google. Ook heeft Google richtlijnen voor robots.txt opgesteld met technische achtergrondinformatie wanneer je er nog meer in wilt verdiepen.
Heb je na het lezen van dit artikel nog meer vragen over het robots.txt bestand, of wil je het instellen ervan liever overlaten aan specialisten in zoekmachine optimalisatie? Neem dan gerust contact op met onze SEO specialisten! Volg ons ook op LinkedIn en Instagram voor de laatste ontwikkelingen op het gebied van online marketin